
Aplikasi AI generatif DeepSeek kini pantas menjadi ungkapan popular dalam bidang teknologi. Ia begitu popular sehingga jenama AI generatif lain berebut-rebut untuk mengatakan bahawa produk atau model bahasa besar (LLM) mereka lebih berkuasa atau mempunyai penaakulan (reasoning) yang lebih baik dan sebagainya.
Sungguh pun begitu, kami lihat bahawa ramai yang terlepas pandang mengapa DeepSeek menjadi begitu popular pada asalnya, jadi berikut adalah semua yang perlu anda ketahui tentang DeepSeek setakat ini, seperti yang dikarang oleh penulis TechNave Bahasa Inggeris:
Mengapa DeepSeek mencipta nama besar untuk dirinya sendiri?
Prestasi AI yang setanding LLM lain, dengan kos yang jauh lebih rendah
DeepSeek telah mengurangkan kos pembangunan dan penggunaan model AI termaju dengan ketara berbanding platform seperti ChatGPT. Dengan melatih model terbaharu mereka, DeepSeek-R1, ia menelan belanja kira-kira $5.6 juta (~RM24.9 juta) manakala model serupa daripada pesaing mempunyai kos latihan antara $100 juta (~RM445 juta) hingga $1 bilion (~RM445 bilion).
Bagi para pengguna pula, DeepSeek menawarkan struktur harga yang lebih berpatutan. Perkhidmatan API-nya berharga 1 yuan (~RM0.62) untuk setiap 1 juta token input dan 16 yuan (~RM9.91) untuk setiap juta token output. Sebaliknya, model pesaing lain mengenakan bayaran $15 (~RM66.8) untuk setiap juta token input dan $60 (~RM267) untuk setiap juta token output. Perbezaan besar dalam kos pembangunan dan penggunaan inilah yang menjadikan DeepSeek pilihan yang lebih menjimatkan kos untuk pengguna yang mencari keupayaan AI termaju.
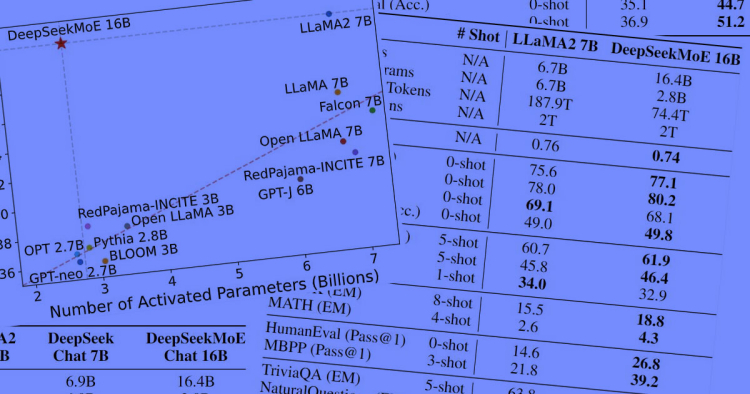
Kaedah pengiraan Mixture-of-Experts (MoE) mengurangkan overhed pengiraan
Kaedah Campuran Pakar (MoE) DeepSeek meningkatkan kecekapan dengan hanya memanggil pakar yang diperlukan oleh gesaan (prompt). Ini mengurangkan kos dan permintaan pengiraan. Ia juga meningkatkan prestasi dengan menggunakan “pakar” khusus untuk tugas yang berbeza, memastikan respons yang lebih tepat. Sebagai perbandingan, AI lain biasanya memilih seorang pakar besar yang mengetahui segala-galanya.
MoE juga membolehkan penskalaan (scalability) yang lebih baik, penggunaan tenaga yang lebih rendah dan pembayaran lebih mampu milik berbanding model AI yang lebih padat. Walau bagaimanapun, ia menambah kerumitan latihan kerana penghalaan pakar.
Kecekapan tenaga yang lebih baik
Memandangkan kaedah Campuran Pakar DeepSeek hanya mengaktifkan sebahagian kecil parameternya untuk setiap gesaan, ini mengurangkan pengiraan dan beban GPU. Ini menurunkan penggunaan kuasa, mengurangkan penjanaan haba dan berskala dengan cekap tanpa meningkatkan permintaan tenaga. Kaedah ini juga mengoptimumkan latihan dengan hanya memberi tumpuan kepada pakar yang berkaitan dan mengurangkan pembaziran pengiraan.
Laporan awal menunjukkan bahawa DeepSeek mempunyai sehingga 90% penggunaan tenaga yang lebih rendah dan pengurangan 92% dalam jejak karbon berbanding infrastruktur yang setanding dengannya, bagi menghasilkan kecekapan tenaga yang lebih baik sebanyak 20–30%. Ini seterusnya menjadikannya lebih mampan.
Penggunaan awal dan respons semasa terhadap DeepSeek
Sifat sumber terbuka (open source) DeepSeek juga bermakna ia lebih mudah untuk dikongsi dan dibangunkan. Walau bagaimanapun, pengguna awal DeepSeek telah menyatakan bahawa walaupun AI ini nampaknya memberikan respons yang lebih menyerupai manusia berbanding pesaing, ia mungkin kekurangan daripada segi pengetahuan umum. Ini menunjukkan bahawa latihan untuk model LLM DeepSeek mungkin tidak menyeluruh seperti yang lain, yang juga boleh menunjukkan mengapa ia hanya berharga $5.6 juta (~RM24.9 juta) berbanding 100 juta (~RM445 juta) pada LLM lain.
Respons terhadap DeepSeek di seluruh dunia adalah pelbagai. Walaupun ia menjadi Pembantu AI yang paling banyak dimuat turun dalam App Store Apple di Amerika Syarikat, ia juga menerima “layanan TikTok” di Itali kerana kebimbangan privasi. Kembali ke China, ia nampaknya telah mencetuskan perang harga daripada syarikat-syarikat teknologi China lain yang menawarkan perkhidmatan serupa. Selain itu, DeepSeek sendiri melaporkan telah menjadi sasaran serangan siber, mungkin dari AS.
AMD telah pun mendedahkan cara menjalankan DeepSeek pada sistem yang menggunakan komponen AMD+Radeon manakala saham NVIDIA telah menyaksikan penurunan yang ketara.

Kesimpulan – Petanda AI masa hadapan?
Hasil daripada kaedah inovatif dan kecekapan tenaga mereka, kami menjangkakan DeepSeek akan kekal popular untuk seketika lagi. Lebih baik jika pesaing AI lain tidak cuba menguar-uarkan kebaikan mereka secara keterlaluan berbanding kekurangan DeepSeek yang jelas. Selain itu, kami ternanti-nanti syarikat AI yang akan menyelesaikan isu kecekapan tenaga AI generatif dan kekurangan lain dengan lebih baik.
Walau bagaimanapun, dengan cara pihak tertentu yang ingin mengekalkan penguasaan pasaran melalui kawalan bekalan cip AI, nampaknya negara-negara seperti Malaysia yang berminat dengan AI mungkin tidak mempunyai pilihan lain selain memberi tumpuan kepada DeepSeek dan model-model AI lain yang kurang memerlukan sumber.

Menurut DeepSeek sendiri, mereka hanya mahu mencapai AGI atau Kecerdasan Am Buatan (Artificial General Intelligence). Sebaik-baiknya, kita semua akan mencapai AGI dengan lebih pantas jika kita semua bekerjasama tetapi sesetengah pihak hanya terpaku pada idea penguasaan.
Beritahu kami di Facebook jika artikel ini membantu pemahaman anda terhadap DeepSeek dan teruskan bersama Rakan Teknologi Utama Malaysia untuk berita teknologi terkini.
[Diterjemahkan daripada TechNave]




